Cosine similarity python sklearn example | sklearn cosine similarity
cosine similarity python sklearn example : In this, tutorial we are going to explain the sklearn cosine similarity.
It trends to determine how the how similar two words and sentences are and used for sentiment analysis.
The cosine of 0 degrees is 1 and less than 1 for any angle of interval (0, 3.14).
The cosine distance is used for complement in positive space where the distance is not proper as it has triangle inequality, formally inequality to repair the triangle.
The advantage is that it has low complexity for sparse vectors only to none zero dimensions.
The name of cosine similarity is orchini and tucker coefficient of congruence.
It will determine the dot product between vectors of sentences to find the angle to derive similarity.
If vectors are parallel to each other then we say that each documents are similar and if they are orthogonal means square matrix whose columns and the rows are orthogonal vectors.
It is the metric used to measure how similar the document is irrespective to size.
Also they measure the cosine angle between two vectors in multidimensional space.
The smaller the angle the cosine similarity is higher.
The commonly used approach to match documents is based on counting the maximum number of common words between documents.
The cosine similarity will help the fundamental flaw in Euclidean distance or account the common words.
Dot product:-
It is called the scalar product since the dot product of two vectors is given as a result.
Example:-
Vector (A) = [5, 0, 2]
Vector (B) = [2, 5, 0]
The dot product is:-
Vector (A).vector (B) =52+02+2*0=10
Now the geometric definition of dot product is the dot product of two vectors is equal to product of lengths by the angle between them. The cosine angle decreases as the cosine similarity increases.
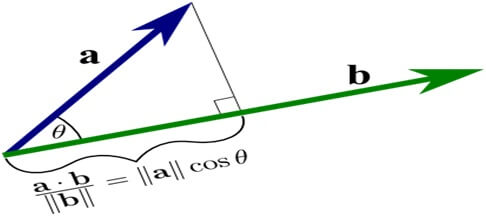
Cosine similarity python sklearn example using Functions:-
Nltk.tokenize: used foe tokenization and it is the process by which big text is divided into smaller parts called as tokens.
Nltk.corpus:-Used to get a list of stop words and they are used as,”the”,”a”,”an”,”in”.
Example:-
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
x=”I love horror movies”
y=”Lights out is a horror movie”
x_list=word_tokenize(X)
y_list=word_tokenize(Y)
sw=stopwords.words (‘English’)
11= []; 12= []
x_set= {w for w in x_list if not w in sw}
y_set= {w for w in Y_list if not w in sw}
rvector=x_set.union (Y_set)
for w in rvector:
if w in x_set:l1.append (1)
else: 11.append (0)
if w in y_set:12.append (1)
else: 12.append (0)
c=0
for I in range (len (rvector)):
c+=l1 [i]*l2 [i]
cosine=c/float ((sum (l1)*sum (l2)) **0.5)
print(“similarity:” cosine)
Output:-
Similarity: 0.666666666
Computing cosine similarity in python:-
The three texts are used for the process of computing the cosine similarity,
Doc Trump (A):-
He became president after winning the political election also lost support of some republican friends.
The putin was friend of trump.
Doc trump election (B):-
Trump says that putin has no interference in election.
And claimed the putin as friend who had nothing to do with election.
Documents= [doc_trump, doc_election, doc_putin]
For computing we need word count of words in each document.
CountVectorizer from scikit-learn used for computing and the sparse matrix obtained at output.
sklearn cosine similarity Example:-
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
count_vectorizer=CountVectorizer (stop_words=’English’)
count_vectorizer=CountVectorizer ()
spares_matrix=count_vectorizer.fit_transform (documents)
doc_term_matrix=sparse_matrix.todense ()
df=pd.DataFrame (doc_term_matrix, columns=count_vectorizer.get_feature_names (), index= [‘doc_trump’,’doc_election’,’doc_putin’])
df
Output:-
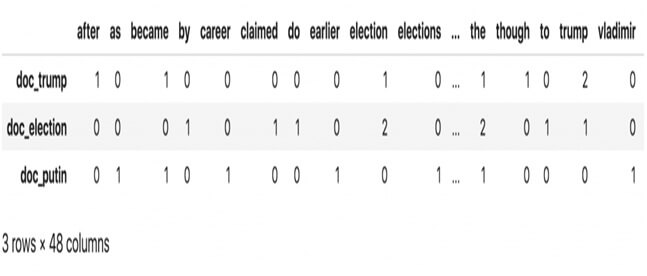
Dot-matrix:-
We can use cosine_similarity to get final output and take the document as the data frame as well as a sparse matrix,
Example:-
from sklearn.metrics.pairwise import cosine_similarity
print (cosine_similarity (df, df))
Output:-
[[1. 0.48]
[0.4 1. 0.38]
[0.37 0.38 1.]
The cosine similarities compute the L2 dot product of the vectors, they are called as the cosine similarity because Euclidean L2 projects vector on to unit sphere and dot product of cosine angle between the points.
It will accept the scipy.sparse matrices for functionality.
Computing the functionality between x and y,
K(X, Y) = <X, Y> / (||X||*||Y||)
Then L2 is the normalized data function which is equivalent to the linear kernel.
Soft cosine similarity:-
Consider a set of documents say food and have semantic matrix as it gives higher scores belonging to the same topic and a lower score for different topics.
Example:-
‘president’vs’prime minister’,’food’vs’Dish’,’Hi’vs’Hello’.
Now for converting words into the respective vectors and then computing it.
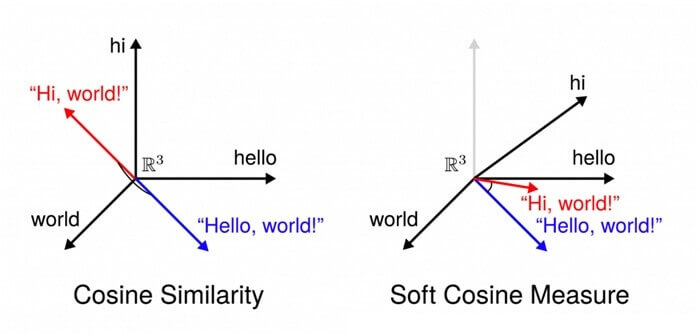
sklearn cosine similarity Example:-
import gensim
from gensium.mayutils import softcossim
from gensim import corpora
import gensim downloader as api
from gensim.utils import simple_preprocess
Print (gensim_version)
fasttext_model300=api.load (fasttext-wiki-news-subwords-300‘)
Computing the soft cosine similarity:-
print (softcossim (sent_1, sent_2, similarity_matrix))
>0.56
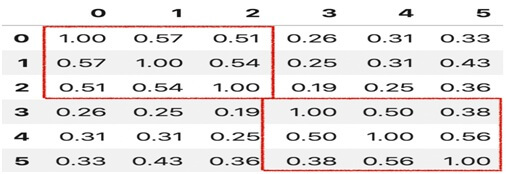
Example of soft cosine matrix:-
import numpy as np
import psndas as p
def create_soft_cossim_matrix (sentences):
len_array=np.arange (len (sentences))
Xx, yy=np.meshgrid (len_array, len_array)
cossim_mat=pd.DataFrame([[round(softcossim(sentences[i],sentences[j],similarity_matrix),2)for I,j in zip(x,y)]for y,x in zip(xx,yy)])
return cossim_ma
soft_cosine_similarity_matrix (sentences)
Parameters:-
Xndarray (n_samples_x,n_features) |
It is input data |
yndarray (n_samples_y,n_features) |
It s also a input data and if none the output will be pair wise similar between samples in x. |
Dense_outpuboolean |
Weather to return the dense value output when input is sparse. |
Return |
Array with the shape(n_samples_x,n_samples_y) |























