gensim doc2vec tutorial for beginners
gensim doc2vec tutorial for beginners: The gensim doc2vec is introduced by the le and micolov. The doc2vec will compute vector for a word in a corpus and compute a feature vector for every document in the corpus. The wordvec will work on intuition and represent the surrounding words. The doc2vec is the unsupervised algorithm to generate sentences, phrases, and documents. The vectors are generated by the doc2vec and used for tasks like finding out similarity between sentences, phrases. The models like RNN are captured in sentence vector and doc2vec are word order independent. If input is corpus in one with misspelling this algorithm is used as the ideal choice. The skip thought vector is another option based on the problem-solving technique. They are used to generate vectors where the predicting sentences are adjacent and assumed semantically. The doc2vec is an extension for word2vec towards the documents and intention is encoding the docs.
The doc will add placeholder input neurons for each doc like id or hash-value.
The doc2vec is nice but has problems which are to be resolved and handle full documents and sentence.
The doc2vec will modify the word2vec algorithm to unsupervised learning for large blocks.
In all kinds of clustering or classification tasks, we have to represent a document as a vector.
We use vector representations on using these vector representations by topic modeling, TF-IDF, and a bag of words were representations we previously looked at.
Then building on Word2Vec the researchers have also implemented a vector representation of documents popularly called Doc2Vec.
We can use the power of the semantic understanding of Word2Vec to describe documents in any dimension.
The method of using word2vec information for documents is by simply averaging the word vectors of that document.
To implement document vectors Mikilov and Le simply added another vector.
There are two flavors of doc2vec,
- Distributed memory model of paragraph vectors (PV-DM).
- The distributed bag of words version of paragraph vectors (PV-DBOW).
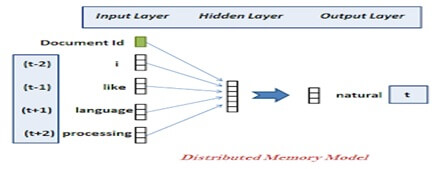
Distribute memory model:-
It is similar to continuous-Bag-of-words (CBOW) in word2vec that attempts to guess output.
The difference between skip-gram and distribution bag of words is using target words as input.
It takes the document ID as input and tries to predict sampled words from the document.
It is a document version of the word2vec and the idea is to convert a document into vectors.
They use two things like labels and content.
The input to doc2vec is iterating of the labeled sentence and each object represents a single sentence.
Single sentence consists of two simple lists the first is a list of words and the second is a list of labels.
Distributed Memory DM:-
It is analogous to the CBOW model in Word2vec the paragraph vectors are obtained by training a neural network on the task of inferring a center word.
They are based on context words and a context paragraph.
Mikolove & Al have implemented the DM model in two different ways by using the average calculation process.
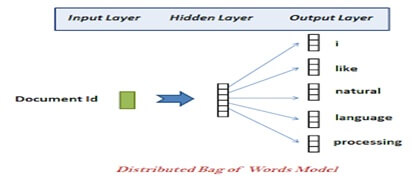
Distributed Bag of Words DBOW:-
The model is analogous to the Skip-gram model in Word2Vec.
Vectors are obtained by training a neural network on the tasks of predicting a probability distribution of words.
The implementation and comparison is done using a Python library Gensim,
- Word2vec
- DBOW (Distributed Bag of Words)
- DMC (Distributed Memory Concatenated)
- DMM (Distributed Memory Mean)
- DBOW + DMC
- DBOW + DMM
That representation will take dataset as input and produce the word vectors as output. Then construct a vocabulary from training text data and learn vector representation of words.
The vectors can be used for sentiment analysis where we use simple Neural Network for training and evaluated the result on the validation set.























