k nearest neighbor sklearn | knn classifier sklearn
k nearest neighbor sklearn : The knn classifier sklearn model is used with the scikit learn. It is a supervised machine learning model. It will take set of input objects and the output values. The K-nearest-neighbor supervisor will take a set of input objects and output values. The model then trains the data to learn and map the input to the desired output. The K-NN will work by taking data point at k closest parts used for ML. It is a lazy algorithm and does not have a specialized phase and used for all training data points. It is a very useful feature for real-world data and follows the assumptions as uniform distribution, etc. The algorithm wills simply calculate the distance b of data point to training data points. The distance can be Edclidean or manhattan and select the nearest data point. Here k can be any integer and assign data points to a class of k points. The neighbors of k work as the algorithm to store classes and new classes based on the measure.
knn classifier sklearn | k nearest neighbor sklearn
It is used in the statistical pattern at the beginning of the technique.
The k nearest neighbor is also called as simplest ML algorithm and it is based on supervised technique. The algorithm will assume the similarity between the data and case in similar categories. This algorithm is used for the regression and classification also used for classification problems. Also called as the non-parametric algorithm and do not make any assumption on underlying data. The KNN algorithm store dataset and gets new data then classifies it into many similar data.Parameters |
Description |
n_neighboursint.optional |
Number of neighbor to use default for neighbors. |
weightstr |
Used in the prediction |
Algorithm{‘auto’,’ball_tree’,’kd_tree’,’brute’} |
Ball_tree use BallTree |
|
Kd_tree will use K.DTree |
|
Auto will attempt to decide the algorithm based on values. |
Leaf_sizeint |
It will affect the speed of construction and query and memory used to store the tree. |
pinteger |
If p=1 then by using manhattan_distance and Euclidean distance for p=2 is used. |
Metric_paramsdict |
The keyword for metric function. |
Attributes |
Class: used to label to classifier |
attributes |
Class_array of shape is the class labels known to classifier. |
Effective_metric_params_dict |
Also called keywords for metric function. |
Outputs_2d_bool |
False when the shapes are nsample during fit or true. |
Working with the KNN algorithm?
The k is number if nearest neighbor. The neighbor number is the core deciding factor and odd number.
Example:-
If k=1 then the algorithm is known as a nearest neighbor algorithm.
Suppose P1 is a point which the label needs to predict then closest point to p1 and the nearest point to assign P1.
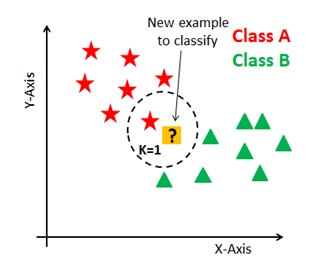
Here p1 for which label is needed to predict. Firstly you have to find the closest point and classify point by a vote of k neighbour.Then object for class with the vote is taken as prediction.
Data:-
The data is an important aspect of any technique of the algorithm.
Each row in the data will contain information on how the player performed in the 2013-2014 season.
Columns are,
Pos-position of player
Player-name of player
g-number of games the player was
gs-number of games the player started
Pts-it is the total points of player scored
Example:-
import pandas
with open (“nba_2013.csv”,’r’) as csvfile:
nba=pandas.read_csv (csvfile)
print(nba.coloumns.values)
Output:-
[‘player’ ‘pos’ ‘age’ ‘bref_team_id’’g’ ‘gs’ ‘mp’ ‘fg’ ‘fga’ ‘fg’.’’x3p’ ‘x3pa’ ‘x3p.’x2p’ ‘x3p’ ‘efg.’’ft’ ‘fta’ ‘ft.’ ‘orb’ ‘drb’ ‘trb’ ‘ast’ ‘stl’ ‘blk’ ‘tov’ ‘pf’ ‘pts’ ‘season’ ‘season_end’]
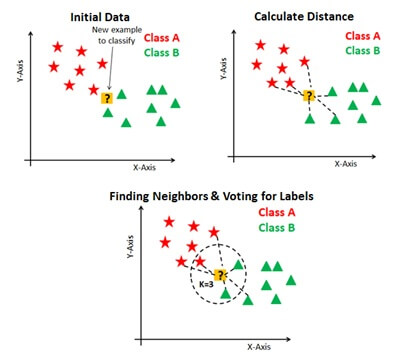
Let’s consider an algorithm with a simple example:-
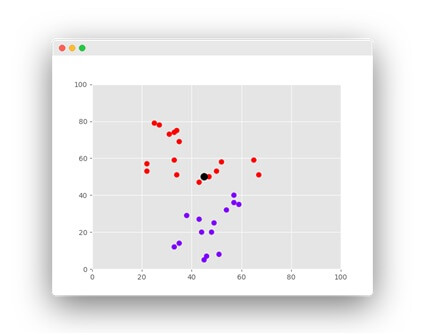
Suppose the dataset is of two variables and plotted as,
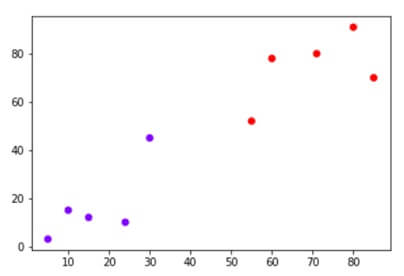
The task is used to classify the data point with X into a blue class and or red class.
The data points are x=45and y=50.consider value of k is 3.
The algorithm will start by calculating the distance of point x from all points.
Then we have to find the nearest points with distance to point x.The three nearest points have been encircled.
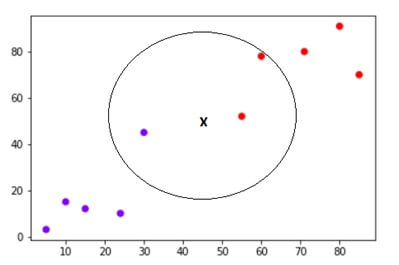
The first step of KNN algorithm will assign new point to class in which majority of nearest point belong.
The KNN algorithm is used to assign new point to class of three points but has nearest points.
The algorithm is used for regression and classification and uses input consist of closest training.
The cases which depend are,
- K-nearest classification of output is class membership.
- K-nearest regression the output is property value for the object.
The k neighbor simply calculates the distance of new data point to other data points.
The second will select the nearest data point where the k in integer form.
The third will assign data point to class and majority of k data point.
The task will classify a new data point with x in the Red class or blue class.
knn classifier sklearn Example:-
Suppose the image creature is present and it looks the same as a cat and dog but you want to know either it is cat or dog.
For this we use the KN algorithm and works on a similarity measure.
The model will find same feature of new data set to cats and dogs images which are based on features it put to see it is dog or cat.
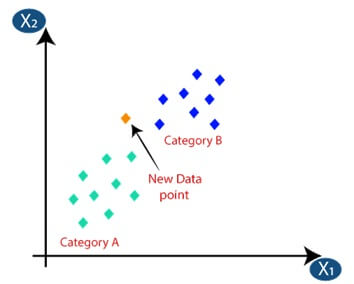
First, choose the number of neighbor then choose k=5.
Then we will calculate Euclidean distance between the points. The meaning of Euclidean distance is the distance between two points.
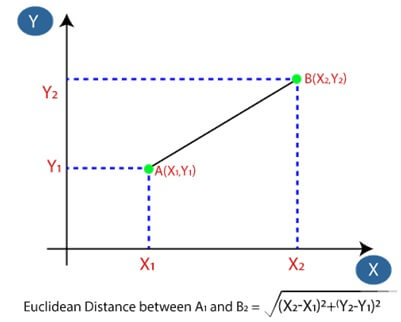
After calculation, we get the distance of Euclidean and nearest neighbor as there are 3 neighbors in A and 2 in B.
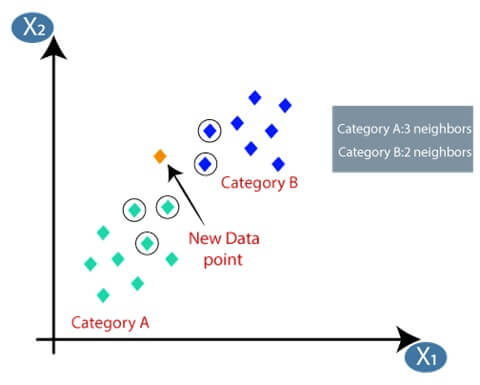
Selecting the value in KNN algorithm:-
- No fixed way to determine the value for k so we need some values to find best of them.
- The low value for k is k=1 and k=2.
- A large value of k is good but some are difficult.
Steps for implementation of KNN algorithm:-
- Fitting KNN algorithm to the training set.
- Data preprocessing step.
Then predicting the test result. - The accuracy of the test.
- Visualization of a test set result.
knn sklearn Example:-
import numpy as nmimport matplotlib as nm
import pandas as pd
data_set=pd.read_csv (‘user_data.csv’)
x=data_set.iloc [: [2, 3]].values
y=data_set.iloc [: 4].values
from sklearn.model_selection import train _test_split
x_train, x_test, y_test=train_test_split(x, y, test_size=0.25, random_state=0)
from sklearn.preprocessing import standardscaler
st_x=standardScaler ()
x_train=st_x.fit_transform (x_train)
x_test=st_x.transform (x_test)
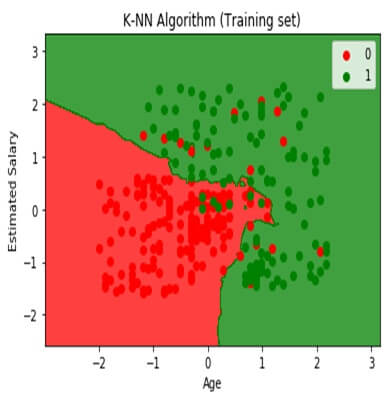
Visualizing the training set result:-
We are going to visualize the training set for K-NNmodel and the code will remain the same as the logistic regression except for the name of graph.
Example:-
from matplotlib.colours import listed colormap
x_set, y_set=x_train, y_train
x1,x3=nm.meshgrid(nm.arange(start=x_set[:,0].min()-1,stop=z_set[:,0].max()+1,step=0.01),nm.arange(start=x_set[:],1).min()-1,stop=x_set[:1,].max()+1,step=0.01)
mtp.contourf(x1,x2,classifier.predict(nm.array([x1.ravel(),x2.ravel()]).T).reshape(x1.shape),alpha=0.75,cmap=listedcolormap((‘red’,’green’)))
mtp.xlim(x1min (), x1.max ())
mtp.ylim (x2.min (), x2.max ())
for i, j in enumertate (nm.unique (y_set)):
mtp.scatter(x_set[y_set==j,0],x_set[y_set==j,1],c=listedcolormap(‘red’,’green’))(i),label=j)
mtp.title (‘K-NN algorithm (Training set)’)
mtp.xlabel (‘age’)
mtp.xlabel (‘estimated salary’)
mtp.legand ()
mtp.show ()
k nearest neighbor sklearn Advantages:-
- It is very simple to implement
- It is noisy training data.
- It is effective if data is large.
- It is a memory-based and classifier which immediately adapts and collects data.
- The complexity for new samples grows linearly with the number of samples in the dataset scenario.
- It is a lazy learning and non-parametric algorithm. The non-parametric means no assumption for data distribution.
- The lazy algorithm means it does not need any training data points for model generation.
- The training data is used in the testing phase and makes training faster and testing slower, costly.
Disadvantages:-
- It is always needed to determine the value of k which is complex some time.
- The cost of computation is high because of calculating the distance between data points for all training samples.
knn classifier sklearn Applications:-
- The collection of characteristics to compare people with similar financial features to the database to do the credit ratings.
- Classify people to be one party or another to predict politics.
- Then the recognition for image recognition and video recognition.























