labelencoder sklearn | labelencoder scikit
Labelencoder sklearn : The LabelEncoder in scikit-learn is used to encode the DataFrame of string labels. The data frame has columns above 50 and avoids creating LabelEncoder object for each column. The column LabelEnconder will create the below error and deal with the columns. The fit_transform method in the labelEncoder will follow standard convention for methods as fit_transform(X [, y]). It will use LabelEncoder will accept one argument with the fit(y) and fit_transform(y). The label_encoder is used inside the pipeline or columnTransform.
The fit and fit_transform method in original encoder will follow scikit-learn,
_init_ ($self, /*arg, **kwargs)
Initialize will help (type (self)),
Fit(y) [source]
Fit labelencoder sklearn :-
Parameter:-y: array like shape target values.
Returns:-self: return instance of self.
Fit_transform(y) [source]:-
Parameter:-y: array like of shape target values. [n_samples]
Returns:-self: return instance of self. [n_samples]
Get parameters (deep=True) [source]:-
Parameter:-y: array like shape target values. [n_samples]
Returns:-self: return instance of self. [n_samples]
Inverse_transform(y) [source]:-
Parameter:-y: array like shape target values. [n_samples]
Returns:-y: numpy array of shape [n_samples]
Set_params (**params) [source]:-
It will set an estimator used to work in a simple estimator on nested objects.
Returns: self
Transform(y) [source]
It transforms labels to normalize the encoding.
Class sklearn.preprocessing.LabelEncoder [source]
It will encode labels with a value between 0 and -1.
It is used to target values as y and not the input X.
Labelencoder sklearn Example :-
LabelEncoder is used to normalize the labels as follows,From sklearn import preprocessing
Le=preprocessing.LabelEncoder ()
Le.fit ([1, 2, 2, 6])
LabelEncoder ()
Le.classes
array ([1, 2, 6])
Le.transform [(1, 1, 2, 6)]
array ([0, 0, 1, 2...])
Le.transform [(1, 1, 2, 6)]
Array ([0, 0, 1, 2...])
It is used to transform the non numerical labels to numerical labels.
Methods |
Description |
Fit_transdorm(self,y) |
It will fit label encoder and return encoded labels. |
Fit(self.y) |
It fits label encoder |
Get_params(self[,deep]) |
It gets parameters for estimator. |
Inverse_transform(self,y) |
The method will transform the label back to encoding. |
Set_params(self,\*\*params) |
Set the parameters of estimator. |
Label encoding:-
It is used for converting labels into the numeric form from machine-readable form.
The algorithm will decide how the labels are operated.
It is an important preprocessing step for the structured dataset.
Example:-
Suppose the common height in some dataset is,
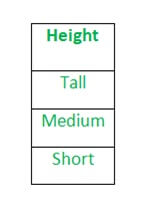
Then applying label encoding, the Height column is converted into:
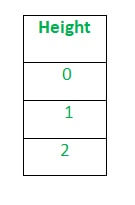
Where 0 is the label for tall and 1 is the label for medium, where 2 is label for short height.
Example:-
import numpy as np
import pandas as pd
df=pd.read_csv (‘.../../data/Iris.csv’)
df[‘species’].unique ()
Output:-
array([‘Iris-setosa’,’Iris-versicolor’,’Iris-virginica’], dtype=object)
Label coding Example:-
from sklearn import preprocessing
label_encoder=preprocessing.LabelEncoder ()
df[‘species’] =label_encoder.fit_transform (df[‘species’])
df[‘species’] =label_encoder.fit_transform (df[‘species’])
df[‘species’] =label_encoder.fit_transform (df [‘species’])
df[‘species’].unique ()
Output:-
array ([0, 1, 2], dtype=int64)
Country variable:-
It converts the variables into the categorical data and use LabelEncoder () from preprocessing library.
Example:-
from sklearn.preprocessing import LabelEncoder
label_encoder_x=LabelEncoder ()
x [:, 0] =label_encoder_x.fir_transform ([x:, 0])
Output:-
Out[15]: array ([2, 38.0, 680000.0],
[0, 43.0, 450000],
[1, 30.0, 5400.0],
[0, 48.0, 6500.0],
[2, 35.0.58000.0],
[1, 41.11, 53000.0],
[0, 49.0.79000.0],
[2, 50.0, 88000.0],
[0, 37.0, 77000.0]], dtype=object)
The LabelEncoder is class of sklearn library the class encoded variable digits.
The ML is between the labelEncoder and one of Hot Encoder.
The encoders are scikit library in python and used to convert the data and text data.
The variables are into categorical variables and vice versa.The task performed is model training and require data to be encoded in numerical format.























