Sklearn minmaxscaler example | minmaxscaler sklearn
Sklearn minmaxscaler example : The minmaxscaler sklearn has the value and it will subtract minimum value in feature by dividing the range.
The difference between maximum and minimum is calculated. Then the shape of the original distribution is preserved.
The feature is used by scaling the given range and translates each range individually as given range on training ser between 1 and 0.
The transform feature is by scaling each feature to the given range.
The eliminator will translate and scale each feature such as it is in a given range on training set.
Transformation is given as, x_std=(x-x.min (axis=0))/ (X.max (axis=0)-X.min (axis=0)).
X_scaled=x_std*(max-min) +min
Where the min, max=feature_range.
The MinMaxScaler will subtract the minimum value and divide it by range.
It is the difference between the original maximum and minimum.
Minmaxscaler sklearn Parameter :-
Feature range: tuple (min.max), default= (0, 1)
Copy:-Boolean is optional by default and ser to false to perform in place the row normalization and avoid copy.
Attributes:-
Min_:-ndarray, shape (n_features,)
As feature for minimum
Scale_: ndarray, shape (n_features,)
As a feature for the relative scaling of data.
Data_min_: ndarray, shape (n_features,)
As feature of minimum seen of data.
Data_min_: ndarray, shape(n_features,)
As a feature of maximum seen of data.
Data_range: ndarray, shape (n_features,)
As feature range (data_max_-data_min_)
Parameters: |
Feature_range:tuple(min,max),default=(0,1): |
Attributes: |
Data_range:-ndarray,shape(n_features,) |
Minmaxscaler Sklearn Methods :-
Methods |
Description |
Fit_transform(X[,y]) |
It will compute the minimum and maximum to be used for scaling purposes. |
Fit_transform(X[,y]]) |
It will fit the data and transform it. |
Get_parms([deep]) |
It will get parameters for estimator. |
Inverse_transform(X) |
The scaling of X according to the feature_range. |
Partial_fit(X[,y]) |
It’s the online computation of max and min on X for later scaling. |
Set_params(**params) |
It will set the parameters of estimator. |
Transform(X) |
The scaling feature of X to the feature of the range. |
Sklearn Minmaxscaler Example :-
from sklearn.preprocessing import MinMaxScaler
data= [[]-1, 2], [-0.5, 6], [0, 10], [1, 18]]
Scaler=MinMaxScaler ()
print(scaler.fit (data))
MinMaxScaler ()
print (scaler.data_max_)
[1.18.]
print(scaler.transform (data))
[[0. 0.]
[0.25 0.25]
[0.5 0.5]
[1. 1.]]
Get_params:-
Parameters:-
Deep: if true it will return the parameters for estimator and sub objects that are estimator.
Return:-
Params: mapping the string to any parameter mapped to their values.
Mro: will list return type method.
Fit_transform: will fit the data and then transform it.
The transformation of X and Y with the parameters that fit_params and return the transformed version of x.
Sample:-
Parameters:-
X: numpy array of shape [n_smaples, n_features]
Training set
Y: numpy array of shape [n_smaples]
Training set
Return:-
X_new: numpy that the array of shape [n_smaples, n_features_new]
Transformed array.
Set_params:-
Setting the parameter of estimator/The method will work on simple estimator as well as nested objects. The former have parameters of the form and update each component of nested objects.
Return:-
Self
Get_param_names:-
Scaling the feature of x according to the feature range.
Parameters:-
X: array-like, shape [n_samples, n_features] it is the input data that will be transformed.
Then compute the maximum and minimum value used for scaling.
Fit:-
Parameters:-
array-like, shape [n_samples, n_features]
X: array_like: The data is used to compute prefecture of the minimum and maximum value used for scaling along the axis.
Inverse transform:-
Used for the undo scaling of x according to the feature_range.
Parameters:-
X: array-like, shape [n_samples, n_features]
The input data will be transformed and cannot be sparse.
Partial fit:-
It is defined as the online computation of max and min on X for the later scaling. Then the processed single batch is intended for fit as it is not feasible due to large samples.
Parameters:-
X: The data used to compute mean and standard deviation used for later scaling along the feature axis.
Y: It is passthrough for the pipeline compatibility.
The scaling technique is used to standardize the feature present in data.
It is performed during the preprocessing to handle the magnitudes and values.
If the scaling is not done then the ML algorithm will tend to the greater weight values and consider lower values of unit of values.
sklearn minmaxscaler Example 2:-
The algorithm that is not using feature scaling method then we can consider the value of 3000 mater which is greater than 5km but not true .so we use the feature to bring values to the same magnitudes.
The techniques to perform feature scaling are,
Standardization:-
It is an effective technique re scales value so that it has distribution with 0 mean and the variance which is equal to 1.

Min-Max normalization:-
It is a technique which is rescales feature or observation value with distribution value between 0 and 1.
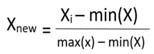
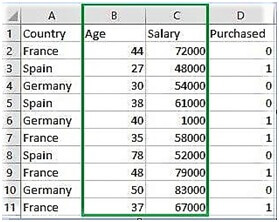
Download dataset:-
Go to the link and then download data for feature scaling.csv.
Example:-
Import numpy as np
Impory matplotlib.pyplot as plt
Import pandas as pd
From sklearn import preprocessing
Data_set=pd.read_csv (‘C: \\users\\dell\\Desktop\\Data_for_Feature_scaling.csv’)
Data_set.head ()
X=data_set.iloc [: 1:3].values
Print(“\noriginal data values: \n”, x)
Min_max_scaler=preprocessing .MinMaxScaler (feature_range= (0, 1))
X_after_min_max_scaler=min_max_scaler.fit_transform(x)
Print(“\nAfter min max Scaling: \n”, x_after_min_max_scaler)
Standardization=preprocessing.standardScaler ()
X_after_standardisation=standardization.fit_transform(x)
Print(“\nafter Standardisation:\n”,x_after_standardisation)
Output:-
Country age salary purchased
0 France 44 72000 0
1 Spain 27 48000 1
2 Germany 30 5 4000 0
3 Spain 38 61000 0
4 Germany 40 1000 1
Original data values:
[[44 72000]
[27 48000]
[30 54000]
[38 61000]
[40 1000]
[35 58000]
[35 58000]
[78 52000]
[48 79000]
[50 83000]
[37 67000]]
After min max scaling:
[[0.333 0.865]
[0. 0.57]
[0.05 0.6]
[0.21 0.73]
[0.25 0.]
[0.15 0.69]
[0.411 0.62]
[0.4 0.9]
[0.4 1.]
[0.19 0.80]]
After standardization:-
[[0.09 0.665]
[-1.15 -0.43]
[-1.15 -0.43]
[-1.15 -0.43]
[-1.15 -0.43]
[-1.15 -0.43]
[-1.15 -0.43]
[-1.15 -0.43]
[-1.15 -0.43]
[-0.9] [-0.16]]























