Web crawler python beautifulsoup
Web crawler python beautifulsoup : The web crawler is an internet bot where the systematically browses are used for the purpose of extracting information. It is an application framework used for writing web spiders that crawler web sites and extract data from them. To obtain data from the website we have to use website crawlers to get the data. They have many components crawlers that use a simple process to download the raw data, process and extract it. The python is an easy-to-use scripting language with many libraries and add-ons for making programs including website crawlers. We use Python as the primary language for development and use libraries that can be integrated with Python to build the final product. The programs request web services from service providers and scrape data from websites. The client will request programs from service on the internet. The web scraping is also the program of client-server interaction and use the tools. They also allow fetching web page content directly. The class which does crawling is called Spider. We feed the spider with a list of the URLs. Then the spider goes to each of the URL and extracts data that is desired and stores them as a list of instances of the class MetacriticItem
Web crawler python beautifulsoup Requirements:-
- Python
- A website
Steps of web crawling:-
Create the basic scraper in the two steps as,
Extract the data from a page that we create and pull down the page and doesn’t do scraping.
Then crawling multiple pages.
Layout the logic:-
What we are coding is a scaled version of what makes Google its millions.
This has more potential and should to expand on it.
Steps:-
- User will enter the beginning url.
- The crawler goes in through the source code and gathers all URL's inside.
- Crawler visits each url in another for loop and gather child url's from the initial parent url.
Code:-
import re, urllib
textfile = file ('depth_1.txt','wt')
print 'Usage - "http://phocks.org/stumble/creepy/" <-- With the double quotes'
myurl = input("@> ")
for i in re.findall('''href=["'](.[^"']+)["']''', urllib.urlopen(myurl).read(), re.I):
print i
for ee in re.findall('''href=["'](.[^"']+)["']''', urllib.urlopen(i).read(), re.I):
print ee
textfile.write(ee+'\n')
textfile.close()
Then we loop the page which we passed, parse the source and return urls.
Need of Web Crawler:-
If Google search was not invented then how much time it would take you to get the recipe for chicken nuggets without typing in the keyword. It is impossible. Google Search is a web crawler which indexes the websites and finds the page for us.
You can build a web crawler to help you achieve.
They work to compile information on subjects from various resources into one single platform.
It is necessary to crawl websites to fuel your platform in time.
- Sentiment Analysis:-
They are also called opinion mining it is the process to analyze public attitudes towards one product and service.
It requires a set of data to evaluate accurately and a web crawler can extract tweets, reviews, and comments for analysis.
Each and every business needs sales leads so how they survive and prosper.
You can scrape email, phone number and public profiles from an exhibitor or attendee list.
Basic Crawler using scrapy demo:-
Following tools are used:-
- Python request (https://pypi.org/project/requests/) used to make a crawler bot
- Parsel(https://parsel.readthedocs.io/en/latest/usage.html) used as a scraping tool
Developing web crawlers with Scrappy is a powerful framework for extracting, processing and storing web data.
Installation:-
It is offered via pip using the following command,
Sudo pip install scrappy
Start a Scrapy project:-
using other Python packages you don’t import Scrappy into an existing Python project. The functions are present as stand-alone packages.
Scrappy start project metactitic
Define the data structure:-
The scrappy uses a class called Item as a container for the crawled data.
To define crawled item we write our class which is derived from the basic Item class.
From scrappy. item import Item, Field
Class MetacriticalItem (Item):
“”
Class for the item retrieved by scrappy.
“”
Title=field()
Link=field()
Cscore=field()
Data=field()
Desc=field ()
Exporting data:-
You need data to be presented as a CSV that you can use the data for analysis.
To save a CSV file the process is open settings.py from project directory and add lines as,
Feed_format=”csv”
Feed_uri=”aliexpress.csv”
After saving return scrappy crawl aliexpress_tablets in a directory.
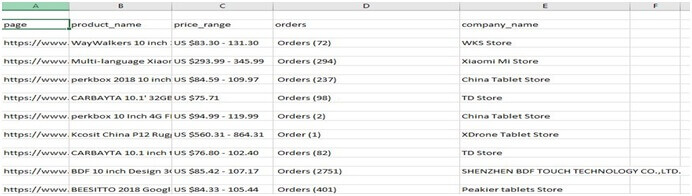
The csv file is as follows,
Feed_Format:-
Will set the format in which you want to store the data.
- +CSV
- +JSON
- +XML
- +JSON lines
Feed_url:-
It will give the location of a file and store the file on local file or an FTP
Example:-
Import scrappy
Class Alisxpress TabletsSpider (scrappy.Spider):
Name=’aliexpress_tablets’
Allowed_domains= [‘aliexpress.com’]
Start_urls= [‘https: //www.aliexpress.com/category/200216607/tablets.html? site=glo&g=y&tag=’]
Custom_settings= {‘FEED_URI’:”alisxpress_ %( time) s.json”,’FEED_FORMAT’:’json’}
Def parse (self, response):
Print(“processing:”+response.url)
Product_name=response.css (‘.product:: text’).extract ()
Price_range=response.css (‘value:: text’).extract ()
Orders=response. path (“//em [@title=’Total Orders’]/text ()”).extract ()
Company_name=response.xpath (“//a [@class=’store$p4pLog’]/text ()”).extract ()
Row_data=zip (product, price_range, orders, company_name)
For item in row_data:
Scraped_info= {‘page’:response.url,’product_name’: item [0],’price_range’: item [1],’orders’: item [2],’company_nmae’: item [3],}
Yield scraped_info

The Program which browses the World Wide Web for the purpose like indexing in case of search engines.
To create a web crawler we need to get familiar with the architecture to build it and have to do a little digging on own.
- Web Page Retriever: The program that goes and fetches web pages from the WWW.
- Extractor: used to extract the links and other data from the webpage’s.
- Links collector: It is a structure that saves the links so that they can be visited further.
- Data Storage: It is a file or a database to save all the data that you need.
We have to choose it from the open sources of web crawler for data mining.
A2A























