Web scraping python beautifulsoup tutorial with example
Web scraping python beautifulsoup tutorial with example : The data present are unstructured and web scraping will help to collect data and store it. There are many ways of scraping websites and online services. Use the API of the website. Example, Facebook has the Facebook Graph API and allows retrieval of data posted on Facebook. Then access the HTML of the webpage and extract useful data from it. This technique is called as web scraping or web harvesting or web data extraction.
Steps involved in web scraping python beautifulsoup :-
- Send a request to the URL of a webpage which you want to access.
- Then the server will respond to the request by returning the HTML content of the webpage.
- After accessing data from HTML content we are at the left task of parsing data.
- We need to navigate and search trees that we create a task.
Installing required third party library:-
Easy way to install the library in python to use pip and used to install and manage packages in python.
Pip install requests
Pip install html5lib
Pip install bs4
Then access HTML content from the webpage:-
Import requests
URL=http://www.geeksforgeeks.org/data-structures/
R=requests. get (URL)
Print (r.content)
- First, the step is to import request library and specify URL of webpage which you want to scrape.
- And send an HTTP request to URL and then save response from the server in response object called r.
- Also print r.contemt ton get rawHTML content of webpage.
Parse HTML content:-
Import requests
From bs4 import Beautifulsoup
URL=”http://www.values.com/inspirational-quotes”
R=requests. get (URL)
Soup=Beautifulsoup (r.content,’html5lib’)
Print(soup.prettify ())
The library in beautifulsoup is build on top of the HTML libraries as html.parser.Lxml.and the it will specify parser library as,
Soup=BeautifulSoup (r.content,’html5lib’)
From above example soup=beautifulsoup (r.content,’html5lib’)-will create an object by passing the arguments.
Html5lib:-will specify parser which we use.
r.content:-also called as raw HTML content.
Libraries used for web scraping python beautifulsoup :-
We will use the following libraries:
- Selenium: - It is a web testing library and used to automate browser activities.
- BeautifulSoup: -Beautiful Soup is also called Python package for parsing HTML and XML documents and creates the parse trees which are helpful to extract the data easily.
- Pandas: - the library is used for data manipulation and analysis. And also used to extract the data and store it in the desired format.
Automated web scraping can be used to speed up the data collection process.
You can write your code once and it will get the information you want from many times and many pages.
When you try to get the information and if you want to do manually you have to spend a lot of time clicking, scrolling, and searching.
You need large amounts of data from websites that are regularly updated with new content.
The manual web scraping can take a lot of time and repetition.
There is much information on the Web and new information is added.
Python Beautiful Soup and libraries requests both are powerful tools for the job.
If you like to learn with hands-on example you have a basic understanding of Python and HTML.
Web scraping will extract the data and presents it in a format you can easily make sense of.
It is the process of gathering information from the Internet.
HTML tags:-
<! DOCTYPE html>
<html>
<head>
</head>
<body>
<h1> first scraping</h1>
<p>Hello World</p>
<body>
</html>
1. <! DOCTYPE html>: it starts the document with a type declaration.
2 It is contained between <html> and </html>.
3. The script and Meta declaration of the HTML document is between <head>and </head>.
4. HTML document contains visible part between <body> and </body>tags.
5. The title headings are defined with the <h1> through <h6> tags.
6. All paragraphs are defined with the <p> tag.
And useful tags include <a> for hyperlinks, <table> for tables, <tr> for table rows, and <td> for table columns.
HTML tags sometimes come with the id or class attributes.
The id attribute specify a unique id for an HTML tag and the value must be unique within the HTML document.
The class attribute is used to define tags with the same class.
We use of these id and classes to help us locate the data we want.
The rules for scraping:-
We have to Terms and Conditions before you scrape it and be careful to read the statements about the legal use of data and should not be used for commercial purposes.
Do not request data from the website with your program as this may break the website. The layout may change from time to time we have to make sure to revisit the site and rewrite your code as needed.
Scraping Flipchart Website:-
Find the URL that you want to scrape
We are going to scrape the Flipchart website to extract the Price, Name, and Rating of Laptops.
The URL for this page is https://www.flipkart.com/laptops/~buyback-guarantee-on-laptops-/pr?sid=6bo%2Cb5g&uniqBStoreParam1=val1&wid=11.productCard.PMU_V2.
Inspecting the Page
The data is usually nested in tag and inspect the page to see which tag the data we want to scrape is nested.
To inspect the page we just right click on the element and click on “Inspect”.
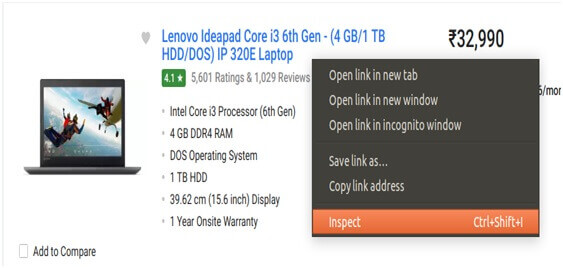
The next step is that you will see a “Browser Inspector Box” open.
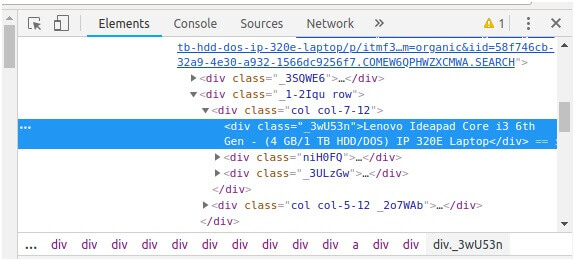
Find the data you want to extract
Then extract the Price, Name, and Rating which are nested in the “div”.
Web scraping python beautifulsoup Example:-
Importing libraries as,
From selenium import webdriver
From beautifulsoup import beautifulsoup
Import pandas as pd
For configuration:-
Driver=webdriver.chrome (“/usr/lib/chromium-browser/chromedriver”)
Products= []
Prices= []
Ratings= []
Driver. get(https://www.flipcart.com/laptops/>https://www.flipkart.com/laptops/~buyback-gauranteelaptops-/pr?sid=6bo%Cb5&uniq
)
Code is as follows:-
content=driver.page_source
soup=Beautifulsoup (content)
for a in soup.finsAll (‘a’, href=True, attrs= {‘class’:’_31qSD5’}):
name=a. find (‘div’, attrs= {‘class’:’_3wU53n’})
price=a. find (‘div’, attrs= {‘class’:’_1vC4OE_2rQ-NK’})
name=a. find (‘div’, attrs= {‘class’:’hGSR34_2beYZw’})
products. append (name. text)
prices. append(price. text)
ratings. append (ratings. text)
Run the code and extract the data
To run the code, use the below command:
Python web-s.py
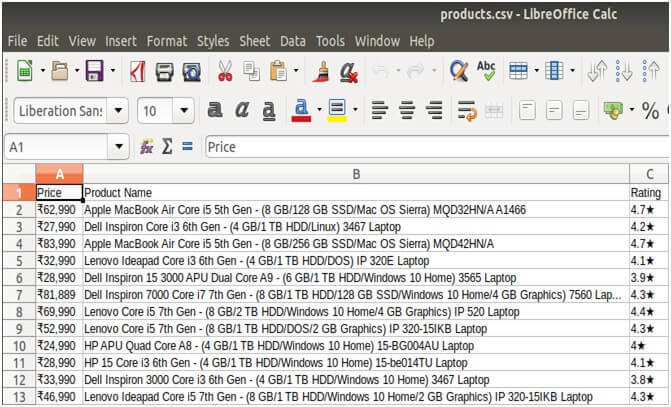
Store the data in a required format:-
df=pd.Dataframe ({‘product name’: products,’ Price’: prices, ‘Ratings’: ratings})
df.to_csv (‘products.csv’, index=False, encoding=’utf-8’)
APIs: An Alternative to Web Scraping:-
The Web is grown out of many sources and combines a ton of different technologies, styles, and personalities.
The API (application programming interfaces) \allow to accessing data in a predefined manner.
You can avoid parsing HTML and instead access the data directly using format.
HTML is a way to visually present content to users.
The process is more stable than gathering the data through web scraping.
APIs are made to be consumed by programs than by human eyes.
Scraping the Monster Job Site:-
You will build a web scraper that fetches Software Developer job listings from the job aggregator site.
Web scraper will parse the HTML to pick out the pieces of information and filter the content for specific words.
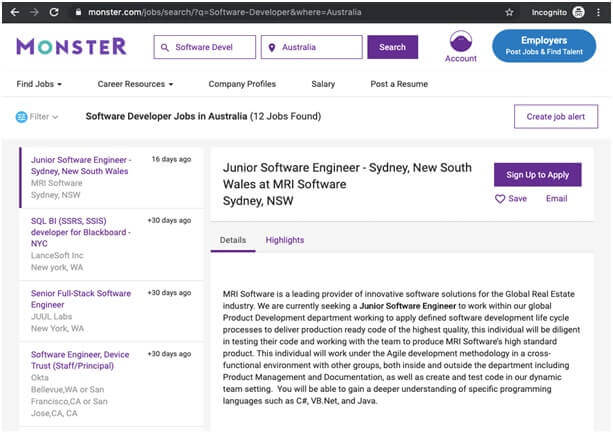
Inspect Your Data Source:-
Click through the site and interact with it just like any normal user would.
In this example you could search for Software Developer jobs in Australia using the site’s native search interface:
Query parameters generally consist of three things:-
- Start: - The query parameters are denoted by a question mark (?).
- Information: - The pieces of information constitute one query parameter that is encoded in key value.
Where related keys and values are joined together by an equals sign.
- Separator: - Every URL can have multiple query parameters which are separated from each other by an ampersand.
Hidden Websites:-
The information is hidden in login and needs to see from the page.
The HTTP request from python script is different than accessing the page from the browser.
Some advanced techniques are also used with a request to access behind the login.
Dynamic Websites:-
They are easy to work with because the server will send you an HTML page which contains all the information as a response.
Then you can parse an HTML response with Beautiful Soup and begin to pick out the relevant data.
Using the dynamic website the server might not send HTML at all and receive JavaScript code as a response.
Parse HTML Code with Beautiful Soup:-
Pip3 install beautifulsoup4
After it import library and create beautiful soup object,
Import requests
From bs4 import Beautifulsoup
URL=’https://www.monster.com/jobs/search/?q=software-developer&where=Austrialia’
Page=requests. get (URL)
Soup=Beautifulsoup (page.content,’html.parser’)
Find the URL you want to scrape:-
To scrape the web for means to find speeches by famous politicians then scrape the text for the speech, and analyze it for how often they approach certain topics, or use certain phrases.
Before you try to start scraping a site we check the rules of the website first.
Rule can be found in the robots.txt file, which can be found by adding a /robots.txt path to the main domain of the site.
Identify the structure of the sites HTML:-
After finding a site to scrap use chrome’s developer tools to inspect the site’s HTML structure.
It is important because more you want to scrape data from certain HTML elements, or elements with specific classes or IDs.
Using the inspect tool you can identify which elements you need to target.
Install Beautiful Soup and Requests:-
There are packages and frameworks, like Scrapy but Beautiful Soup will allow you to parse the HTML.
With Beautiful Soup we need to install a Request library, which will fetch the url content.
The Beautiful Soup documentation has a lot of examples to help get you started as well.
$pip install requests
$pip install beautifulsoup4
Web Scraping Code:-
from bs4 import BeautifulSoup
import requests
librarypage_content = BeautifulSoup (page_response.content, "html.parser")
avariable.textContent = []
for i in range(0, 20):
paragraphs = page_content.find_all("p")[i].text
textContent.append(paragraphs)
Results:-
paragraphs = page_content.find_all ("p") [i].text
This finds all of the <p> elements in the HTML.
The text allows selecting only the text from inside all the <p> elements.
It is messy and so filtering of results using the Beautiful Soup text allows us to get a cleaner return.
Other ways are present to search, filter and isolate the results you want from the HTML.
You can also be more specific, finding an element with a specific class as,
soup.findAll ('div', attrs= {"class":"cool_paragraph"})
This would fine all the <div> elements with the class “cool_paragraph”.























