Word2vec python example
Learn word2vec python example in details. In this tutorial, you will learn how to use the Word2Vec example. Work on a retail dataset using word2vec in Python to recommend products. ... Let me use a recent example to showcase their power.
Example:-
From nltk.tokenize import sent_tokenize, word_tokenizeImport warnings
Warnings.filterwarnings (action=’ignore’)
Import gensim
From gensim.models import word2vec
Sample=open (“c:\\user\\admin\\desktop\\alice.txt”,”r”)
S=sample. read ()
F=s.replace (“\n”,””)
Data= []
For I in sent_tokenize (f):
Temp.append (j.lower ())
Data.append (temp)
Model1=gensim.models.word2vec (data, min_count=1, size=100, window=5)
Print (“cosine similarity between’alice’”+”and ‘wonderland’-CBOW:”model1.similarity (‘alice’,’wonderland’))
Print (“cosine similarity between’alice’”+”and ‘machines’-CBOW:”model1.similarity (‘alice’,’machines’))
Model1=gensim.models.word2vec (data, min_count=1,size=100, window=5,sg=1)
Print (“cosine similarity between’alice’”+”and ‘skip-Gram’-CBOW:”model1.similarity (‘alice’,’wonderland’))
Print (“cosine similarity between’alice’”+”and ‘skip-Gram’-CBOW:”model1.similarity (‘alice’,’machines’))
Output:-
Cosinesimilarity between’alice’ and’wonderland’-CBOW: 0.999
Cosinesimilarity between’alice’ and’machines’-CBOW: 0.9749
Cosinesimilarity between’alice’ and’wonderland’-skip Gram: 0.8854
Cosinesimilarity between’alice’ and’wonderland’-skip Gram: 0.85689
The Output will indicate the cosine similarity between words vectors ‘alice’, ‘wonderland’ and ‘machines’.
Application is:-
- Sentiment analysis
- Speech recognition
- Information retrieval
- Question answering
Develop Gensim Word2Vec Embedding:-
From gensim.models import word2vec
Sentences=[[‘this’,’is’,’the’,’first’,’sentence’,’for’,’word2vec’],[ ‘this’,’is’,’the’,’second’,’sentence’],[‘yet’,’another’,’sentence’],[‘one’,’more’,’sentence’],[‘and’,’the’,’final’,’sentences’]]
Model=word2vec (sentences, min_count=1)
Print (model)
Words=list (model.wv.vocab)
Print(words)
Print (model [‘sentences’])
Model.save (‘model.bin’)
New_model=word2vec.load (‘model.bin’)
Print(new_model)
Output:-
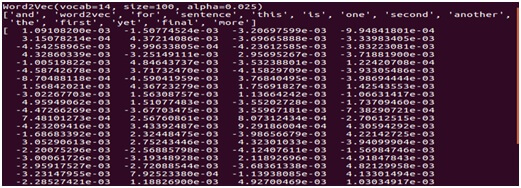
Visualize Word Embedding:-
From gensium.models import word2vec
From sklearn.decompositon import PCA
From matplotlib import pyplt
Sentences=[[‘this’,’is’,’the’,’first’,’sentence’,’for’,’word2vec’],[ ‘this’,’is’,’the’,’second’,’sentence’],[‘yet’,’another’,’sentence’],[‘one’,’more’,’sentence’],[‘and’,’the’,’final’,’sentences’]]
Model=word2vec (sentences, min_count=1)
X=model[model.wv.vocab]
Pca=PCA (n_components=2)
Result=pca.fit_transform(x)
Pyplot.scatter (result [:, 0], result [:, 1])
Words=list (model.wv.vocab)
For I, word in enumerate(words):
Pyplot.annotate (word, xy= (result [I, 0]), result[I, 1]))
Pyplot.show ()
Output:-
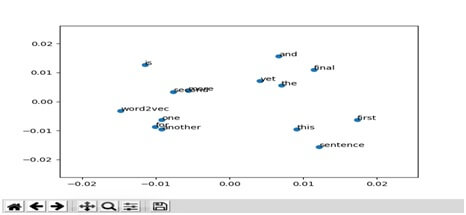
Load Google’s Word2Vec Embedding:-
Sample programming:-
From gensim.models import keyedvectors
Filename=’googlenews-vectors-negative300.bin’
Model=keyedvectors.load_word2vec_format (filename, binary=True)
Result=model, most_similar (positive= [‘women’,’king’], negative= [‘man’], topn=1)
Print (result)
Output:-
























